Darryl Lyons' Blog
ColdFusion, AJAX and web...
Monday, May 29, 2006Google Maps adds Australia and New Zealand
Can't remember if anyone has posted this, cause I read it somewhere, but Google Maps has released Australia and NZ.
Anyway, here is where I work (the triangular building).
Monday, May 29, 2006AJAX Diary: Use TABLEs instead of DIVs
I've recently come the realisation that DIVs are just too much hard work when it comes to writing a stable, responsive and rapid user interface framework for AJAX-applications. Our large AJAX CRM application used DIVs and CSS Expressions heavily to achieve a "windows-like", fluid/scalable user interface. Each time a new pane was added, so were a bunch of CSS rules with expressions in them (absolute positioned elements that reference other elements to set width, height, top, left, etc).
I've now gone back to the dark ages, and converted the entire thing to use good old tables. I can tell you, it is a LOT more responsive. A lot of people may not realise the CSS expressions are evaluated each time something happens in the UI. For example, if you move your mouse, then the CSS expressions are being evaluated. So you can quickly guess that if you're adding more DIVs to the DOM with CSS expressions, you're certainly not speeding things up!
I'll also mention that I am talking about an "application" here -- not a Web site, and our standard platform is Internet Explorer (HTA). You can argue all you like that I should be using DIVs for visual layout, but I think it is more important to use what works.
Tables are just easier and quicker when it comes to GRID layouts...
Sunday, February 19, 2006Using Java BufferedWriter to create CSV files
Someone recently asked me to expand upon my previous post about generating CSV files, and in particular, to focus on the Java method. In my previous post, I concluded that using the Java BufferedWriter class is a much more scalable and stable solution than using the typical concatenate-and-write-once-done method.
Step by Step
There really isn't much to using Java to write to a file. Essentially, there are three steps, 1) create the Java class instances, 2) get the data and write to the buffer, and 3) close the output stream.
Firstly, we instantiate the FileWriter class (which writes to the file) and then the BufferedWriter class, passing the FileWriter instance as a parameter.
-
<cfscript>
-
outputFile = getDirectoryFromPath(GetCurrentTemplatePath()) & "dump.csv";
-
oFileWriter = CreateObject("java","java.io.FileWriter").init(outputFile,JavaCast("boolean","true"));
-
oBufferedWriter = CreateObject("java","java.io.BufferedWriter").init(oFileWriter);
-
</cfscript>
Then, we create the column headers, and loop over the data (query in this case) and write it to the buffer. The Java class manages the size of the buffer internally, so when threshold is reached, it will write to the file.
-
<cfset oBufferedWriter.write("LASTNAME,FIRSTNAME" & chr(13) & chr(10))>
-
<cfloop query="qData">
-
<cfset oBufferedWriter.write(chr(34) & lastname & chr(34) & ",")>
-
<cfset oBufferedWriter.write(chr(34) & firstname & chr(34) & chr(13) & chr(10))>
-
</cfloop>
Lastly, we need to close the output stream, otherwise the file will not be released.
-
<cfset oBufferedWriter.close()>
Full code
-
<cfscript>
-
outputFile = getDirectoryFromPath(GetCurrentTemplatePath()) & "dump.csv";
-
oFileWriter = CreateObject("java","java.io.FileWriter").init(outputFile,JavaCast("boolean","true"));
-
oBufferedWriter = CreateObject("java","java.io.BufferedWriter").init(oFileWriter);
-
</cfscript>
-
-
<cfquery datasource="cfartgallery" name="qData">
-
SELECT *
-
FROM artists
-
ORDER BY lastname, firstname
-
</cfquery>
-
-
<cftimer type="inline" label="Generate CSV">
-
<cfset oBufferedWriter.write("LASTNAME,FIRSTNAME" & chr(13) & chr(10))>
-
-
<cfloop query="qData">
-
-
<cfset oBufferedWriter.write(chr(34) & lastname & chr(34) & ",")>
-
<cfset oBufferedWriter.write(chr(34) & firstname & chr(34) & chr(13) & chr(10))>
-
-
</cfloop>
-
<cfset oBufferedWriter.close()>
-
</cftimer>
Saturday, February 18, 2006AJAX Diary: Race conditions and using cflock
Within traditional web applications, it is highly unlikely that you will come across a scenario where a race condition will ocurr in the current session, unless you are accessing shared scopes. However, within an AJAX application, which is more like a frame-based Web site (remember them?), they can occur only too often.
Background
In our CRM application, there is a method that returns a "client ID". This method checks to see if a record exists in the database, and if not, creates it, and then returns the ID. If it already exists, then it simply returns the record. This record is in a tracking table that we use to reference records in an external system. All tables in our schema join to the tracking table, not the external database. Suffice to say, this method is called in a lot of places where client information is accessed.
<cffunction name="getClientID" returntype="string">
<cfset var local = StructNew()>
<cfset local.qClient = getClientID(arguments.account)>
<cfif NOT local.qClient.recordcount>
// Some logic to create a new tracking ID -- insert into db, etc.
</cfif>
<cfreturn local.qClient.ID>
</cffunction>
Now, you would probably state that there should be a scoped or named lock around this code. However, the likelihood of two sessions trying to create this record at the same time is very remote. Furthermore, most locking in the past has been where you are making changes to shared scopes such as SESSION, APPLICATION or SERVER.
Problem
Our new AJAX interface to our CRM has shown us that we need to be more careful, and use locking more judiciously. The scenario is this. The user clicks on a client record in a search result. This in turn loads the client information card. Three seperate, almost simultaneous, requests are sent to the server to retrieve different pieces of data. Each of the requests just happens to call the aforementioned method at some point. Even though the requests themselves are not occurring at the same time, a race condition is still created...
All three requests are now essentially calling the method, let's call it getClient(), at the same time. The database lookup to determine whether or not the record exists are being performed within a millisecond of each other. All three lookups return no records, so the conditional block of code is executed to insert a new record! So, the end result is three records in the database where there should have only be one!
Solution
Now, we pretty much had two options -- change the calls on the client so that the record check is performed once, or put a named lock around the code, so that we force requests to queue for execution.
We went for the later. Changing all of the calls to the method would require significant refactoring of the model, so that just wasn't an option.
<cffunction name="getClient" returntype="string">
<cfset var local = StructNew()>
<cflock name="getClient.getClientID" timeout="10">
<cfset local.qClient = getClientID(arguments.account)>
<cfif NOT local.qClient.recordcount>
<cflock name="getClient.getClientID.insert" timeout="10">
<cfset local.qClient = getClientID(arguments.account)>
<cfif NOT local.qClient.recordcount>
// Some logic to create a new tracking ID -- insert into db, etc.
</cfif>
</cflock>
</cfif>
</cflock>
<cfreturn local.qClient.ID>
</cffunction>
In the example above, I've put a named lock around the query to the database, and the check of the recordcount. If the recordcount is zero, then we perform another lock, and then do the check all over again. The reason for this is that in the time between acquiring the lock and performing the first check, a database record could have been inserted. The double lock technique just minimises the chance of this happening.
So, why was this only an issue now? Well, the old "traditional" user interface was a HTML page. The processing of the single request was top-down. By that I mean that if various elements of the user interface happened to call the getClient() method, they would be synchronously executed, thereby avoiding the scenario I have described.
Some other resources
Wednesday, February 15, 2006Yahoo! User Interface Library
Yahoo! have released a DHTML UI library for public consumption. Some pretty cool things in there like a calendar control, drag and drop, event management and DOM tools.Wednesday, February 15, 2006Google acquires Measure Map
The blog statistics product I have been using since December 2005 has been acquired by Google. Measure Map, still in alpha, is a very easy to setup and use system, and I have been more than impressed by it over the last couple of months. Jeffery Veen, from the Measure Map team and Adaptive Path, had this to say on the Google Blog.Bringing Measure Map to Google is an exciting validation of the user experience work I've been doing with my partners at Adaptive Path for years. By opening up the app to more bloggers through Google, we hope to help even more people become passionate about their blogs.
Monday, February 13, 2006RSS feeds can be funny - Goodbye Tim
Quite a few blogs have been covering the fact that Tim Buntel is leaving Adobe. I was looking at my MXNA ColdFusion Live Bookmark tonight and I swear I saw these two items in the feed.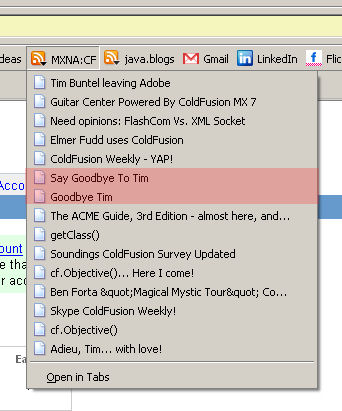
Thursday, January 26, 2006A new browser called Flock
I just came across this new browser called Flock. It is open source software that is built upon the Mozilla code-base -- not as an extension, but as a stand alone product. It looks pretty cool, and they have changed a lot. The browser is currently in developer preview only (but everyone can still download it).
Their main point of difference is the "community integration" they have built in.
Stars & Favourites
You can star your favourite sites using the Star button, and even share them with others using a del.icio.us account. They have changed bookmarks into Favourites, and added more functionality such as collections. You can also tag them using keywords.
Feeds
Flock has all of the Firefox feed options, but also allows you to aggregate different feeds together based on your favourites (you can create "collections" of favourites as well, e.g. News) and view them within the browser.
Blogging
Flock has built-in blogging features, and integrates with many of the top blog providers such as WordPress, Movable Type, Typepad and Blogger. In fact, I've written this post from within Flock. Flock also allows you to "Blog This", so you can highlight passages whilst viewing web pages and blog about it straight away. This is nothing new, but it's nice that it is integrated.
They have also built "The Shelf". This feature is essentially a scrapbook that you can drag all sorts of web content into, so you can blog about it later.
Monday, January 23, 2006Internet Explorer 7 Beta 2 screenshots
ActiveWin.com have posted 50 high-resolution screen shots of Internet Explorer 7 Beta 2. To be honest I wasn't that impressed with the interface at first glance, but I can see that there are a few cool features (like the blank tab). It appears as though IE now has a built-in RSS reader, and formats feeds when you are directly viewing them. I see they have also integrated the Firefox RSS icon.